GSoC 2025,为任何视频构建语义搜索引擎
2025年10月8日 | Akash Kumar | CC-BY-SA-3.0
社区贡献
大家好,openSUSE 社区!
我叫 Akash Kumar,是 openSUSE 组织的 2025 年谷歌夏季代码项目 (GSoC) 实习生。 这篇博客文章重点介绍了我在这次指导计划期间开发的项目,openSUSE 及其导师们帮助我使其成为可能。 今年夏天,我有幸为题为 “创建开源示例微服务工作负载和接口” 的项目做出贡献。 目标是构建一个功能齐全的开源工作负载,该工作负载可以为特定用例提供相关的分析。
对于我的项目,我选择解决一个常见但复杂的问题:搜索视频内部的内容。 这篇博客文章详细介绍了我的 GSoC 项目的成果:一个完整的端到端语义视频搜索引擎。
问题:超越关键词
你有没有试过在一个很长的视频中找到一个特定的时刻? 你可能生动地记得那个场景——一个角色发表了一段关键的演讲,或者有一段美丽的风景的静默镜头——但你记不起确切的时间戳。 你最终来回搓动,浪费几分钟,甚至几个小时。
传统的视频搜索依赖于标题、描述和手动标签。 它有局限性。 它无法告诉你视频内部有什么。
作为我的 GSoC 交付成果的一部分,我着手解决这个问题。 我想构建一个系统,让你能够使用自然语言搜索视频内容。 我想能够问,“找到他们在仓库里讨论秘密计划的场景”,并立即得到结果。
大局:两幕剧
整个系统分为两个主要部分
- 摄取管道 (繁重的工作): 一个离线过程,它接收一个原始视频文件,并使用一套人工智能模型来分析它,理解它,并将这种理解存储在一个专门的数据库中。
- 搜索应用程序 (回报): 一个实时 Web 应用程序,具有后端 API 和前端 UI,允许用户执行搜索并与结果进行交互。
让我们一步一步地了解它的工作原理。
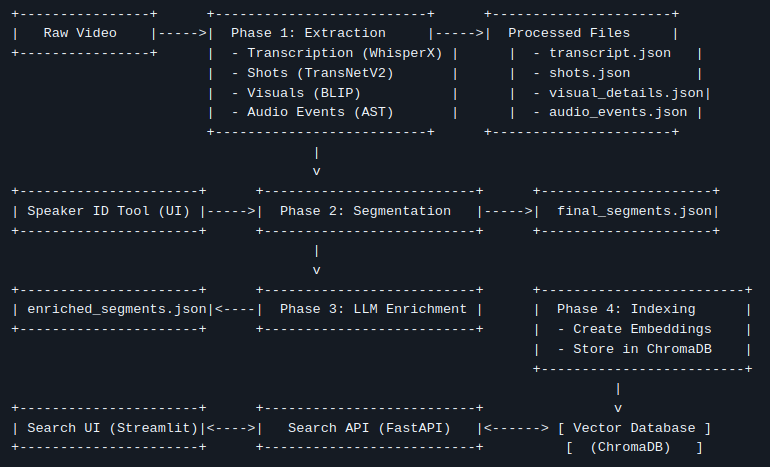
第一部分:摄取管道 - 教机器看电视
这就是魔术开始的地方。 我们获取一个单独的 .mp4 文件,并将其分解成一个丰富的、多模式数据集。
步骤 1:解构视频 (提取)
首先,我们将视频分解成其基本原子:镜头、声音和单词。 我为此使用了一系列专门的人工智能模型
- 镜头检测 (
TransNetV2): 扫描视频以识别每个摄像机剪辑,创建视频结构的“骨架”。 - 转录和说话人分离 (
WhisperX): 提取音频,WhisperX 将所有口语对话转录成文本。 重要的是,它还执行说话人分离——识别谁在说话以及何时说话,分配诸如SPEAKER_00和SPEAKER_01之类的通用标签。 - 视觉字幕 (
BLIP): 对于每个镜头,我们提取一个关键帧,并要求 BLIP 模型生成对它所看到内容的一句话描述(例如,“一个穿着西装的男人站在一辆汽车前”)。 - 动作和音频识别 (
VideoMAE,AST): 我们更进一步,分析视频片段以检测动作(“说话”、“跑步”)和音频以识别非语音事件(“音乐”、“掌声”、“引擎声”)。
完成此步骤后,我们拥有大量的原始、带时间戳的数据。
步骤 1.5:人工参与循环 (说话人 ID)
人工智能知道不同的人在说话,但它不知道他们的名字。 这就是一点人类智慧发挥作用的地方。 管道会自动暂停并启动一个简单的 Web 工具。 在此工具中,我可以查看所有 SPEAKER_00 的对话,播放几个片段来听到他们的声音,并将他们映射到他们的真实姓名,例如“John Wick”。 这一简单的一次性步骤使最终数据更加有用。
步骤 2:寻找叙事 (智能分割)
搜索数百个微小的 2 秒镜头并不是一个很好的用户体验。 我们需要将相关的镜头分组到连贯的场景或片段中。 一次对话可能涉及 20 个镜头,但它只是一个单一的事件。
为了解决这个问题,我开发了一个“边界评分”算法。 它遍历每个镜头,并根据加权组合的因素计算与下一个镜头相比的“变化分数”
- 对话的主题是否发生了变化? (语义文本相似性)
- 视觉效果是否发生了显著变化?
- 说话者是否发生了变化?
- 背景声音或动作是否发生了变化?
如果总变化分数很高,我们就声明一个“硬边界”并开始一个新的片段。 这将一个混乱的镜头列表转换为一个干净的、有意义的场景列表。
步骤 3:添加一层天才 (LLM 丰富)
有了连贯的片段定义,我们引入一个大型语言模型 (如 Google 的 Gemini) 来充当专家视频分析师。 对于每个片段,我们将所有收集到的上下文(转录、说话者、视觉描述、动作)提供给 LLM,并要求它生成
- 一个简短的描述性标题。
- 一个简洁的 2-3 句摘要。
- 一个包含 5-7 个相关关键词的列表。
这增加了一层类似人类的理解,使数据更加丰富和可搜索。
步骤 4:准备搜索 (索引)
最后一步是准备此数据以实现闪电般快速的搜索。 我们使用一个向量数据库 (ChromaDB)。 核心思想是将文本转换为称为嵌入的数值表示。
这里的关键创新是我们的混合嵌入策略。 对于每个片段,我们创建两个不同的嵌入
- 文本嵌入: 基于转录和摘要。 这代表了所说的话。
- 视觉嵌入: 基于视觉字幕和动作。 这代表了所显示的内容。
这些嵌入存储在 ChromaDB 中。 现在,视频已完全处理并准备好进行搜索。
第二部分:搜索应用程序 - 收获回报
所有离线工作都得到了回报。 该应用程序由一个后端“大脑”和一个前端“面孔”组成。
大脑:FastAPI 后端
后端 API 是我们搜索的引擎。 当它收到查询时,它会遵循一个精确的、高速的过程
- 向量化查询: 用户查询被转换为与索引步骤中使用的相同模型相同的类型的数值向量。
- 混合搜索: 它并行查询 ChromaDB 两次——一次针对文本嵌入,另一次针对视觉嵌入。
- 重新排序和融合: 它获取两组结果,并使用称为互易秩融合 (RRF) 的算法将它们合并。 这非常强大。 在文本和视觉搜索中都排名很高的片段(例如,一个角色说“看看直升机”同时屏幕上出现直升机)会获得巨大的分数提升,并跃居列表首位。
- 响应: 后端获取排名最高的结果的完整元数据,并将其作为干净的 JSON 响应发送回前端。
面孔:Streamlit UI
前端是一个简单、干净的 Web 界面,使用 Streamlit 构建。 它具有搜索栏、视频播放器和结果区域。 当你单击搜索结果上的“播放”时,它会立即将视频播放器跳转到该片段的精确开始时间。 它快速、直观且使用起来令人满意。
最终结果和 GSoC 体验
想象一下搜索“仓库里紧张的谈判”。 该系统会在几秒钟内找到它,因为
- 文本搜索匹配关于“交易”、“钱”和“条款”的对话。
- 视觉搜索匹配人工智能字幕,例如“两个男人坐在桌子旁”和“一个昏暗、大型的房间”。
- RRF 算法看到两种信号都指向相同的片段,并将其评为第一结果。
这个项目是一次迷人的多模态人工智能之旅。 它证明了通过结合不同模型的优势,我们可以解构非结构化数据(如视频)并将其重新组合成一个智能、可搜索且真正有用的资产。
我要衷心感谢我的导师 @bwgartner 和整个 openSUSE 社区在整个夏天提供的支持和指导。 与 openSUSE 合作参与 GSoC 是一次宝贵的学习经历。
无目的的搓动时代可能很快就会结束。 如果您有兴趣尝试或贡献,您可以在 GitHub 上找到整个项目:https://github.com/AkashKumar7902/video-seach-engine。